
Using Python and a Raspberry Pi to find a job
When I found out Google was coming to my school’s career fair, I knew I had to secure an interview. Here’s how I used Python, my Raspberry Pi, and web scraping to get their very first slot.
Every year, NC State hosts a virtual career fair for Computer Science students. A couple of weeks before this year’s career fair, they posted the names of the companies who would attend. Among them, I was pleasantly surprised to see some names like:
- Cisco
- Fidelity
- Lucid Software
- Lexis Nexis
and quite a few more. Needless to say, on the morning that time slot registrations opened, I was ready with the career fair webpage pulled up on my phone and laptop. However, when the clock struck 10 and the slots opened up, I was confused. Most companies didn’t post their schedules, and those that did filled up quickly. I refreshed the webpages for a few minutes, but no new schedules appeared. Notably, Google hadn’t opened their schedule.
When I had a spare minute or two between classes, I checked the scheduling webpage to see if companies had posted their schedules, but I quickly realized I was at the whim of the recruiters and I’d have to be very lucky to refresh the webpage at the right time to get an interview before the slots filled up. That afternoon, I started coding my Python script. I had a rough idea of what it would do:
- Navigate to the career fair signup page for each company that hadn't yet posted their time slots. For each company:
- Check if their webpage contains interview slots. If it does:
- Email me with the company name and a link to that company's page
- Remove that company from the list of companies being scraped
If it does not, continue iterating through the webpages.
I also wanted the script to email me occasionally and when errors were encountered so I could stay aware of the process’ health and could be sure that it was still running even when I was away from my apartment or unable to SSH into my Raspberry Pi.
I chose to run the script on my Raspberry Pi for a couple of reasons.
- Firstly because even after years of programming, I just love the idea of having a little machine running code all the time.
- Secondly because I use my laptop and desktop for other things and shut them off sometimes, and I wanted the script to run 24/7. You may think that this is a problem for which cloud computing (AWS or similar) is a solution and you'd be right, but I refer you to #1.
Here’s what the script looks like:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup as bs
from time import sleep
import filecmp
import smtplib
from email.mime.text import MIMEText
from datetime import datetime
# The ID of each employer that hasn't posted their time slots
employer_ids = {
345169: "Google",
343745: "Blue Cross Blue Shield",
346346: "Deustche Bank",
344288: "Kadro Solutions",
347062: "LexisNexis",
344289: "Live Oak Bank",
345187: "SAS Software and Analytics",
343747: "Jurassic"
}
employers_to_check = len(employer_ids)
base_url = "https://app.careerfairplus.com/ncsu_nc/fair/4876/employer/"
checks = 0
options = Options()
options.add_argument('--headless')
sender = "cambotslambot@gmail.com"
recipients = ["cshimes@ncsu.edu"]
password = "PASSWORD_HERE"
def send_email(subject, body, sender, recipients, password):
msg = MIMEText(body)
msg['Subject'] = subject
msg['From'] = sender
msg['To'] = ', '.join(recipients)
with smtplib.SMTP_SSL('smtp.gmail.com', 465) as smtp_server:
smtp_server.login(sender, password)
smtp_server.sendmail(sender, recipients, msg.as_string())
print("Message sent!")
try:
with webdriver.Chrome(options=options) as browser:
while employers_to_check >= 1:
# Send an email every 12 hours so I can know it's still running
now = datetime.now()
if (now.hour == 3 or now.hour == 15) and now.minute == 0:
subject = "Update - I've checked " + str(checks) + " times now!"
body = ""
send_email(subject, body, sender, recipients, password)
# Send an email when it hits some milestones
if checks == 10 or checks == 100 or checks == 1000 or checks % 10000 == 0:
subject = "Milestone! I've checked " + str(checks) + " times now!"
body = ""
send_email(subject, body, sender, recipients, password)
# Iterate through the list of companies to check if they've uploaded a schedule
for employer_id, company in employer_ids.items():
if company == "":
continue
browser.get(base_url + str(employer_id))
# Wait for the page to load!
sleep(4)
# Parse the html into a BS object then find the schedule list section
html = browser.page_source
soup = bs(html, 'html.parser')
results = soup.findAll("section", {"aria-label": "Schedule List"})
# If something is found - that means a schedule has been uploaded!
if len(results) >= 1:
subject = company + " has just opened their schedule for the career fair!!!"
body = "Go go go - here's the link: " + base_url + str(employer_id)
send_email(subject, body, sender, recipients, password)
# Remove that company from the dictionary so I don't get spammed with new emails upon every iteration
employer_ids[employer_id] = ""
# Update the length so the script eventually knows to stop
employers_to_check -= 1
checks += 1
except Exception as e:
# Send an error email
subject = "I don't feel so good boss...."
body = "I encountered an error somewhere. I'm gonna stop running for now. Here's some more detail:\n" + str(e)
send_email(subject, body, sender, recipients, password)
# Send an email when the script is done running
subject = "I'm done!"
body = "It looks like all employers have opened their schedules, so I'm shutting down now. Ciao."
send_email(subject, body, sender, recipients, password)Less than 100 lines in total including comments and import statments. The ‘bot’ (as I ended up calling it) could check each webpage reasonably often, something like 1 to 2 times per minute. Naturally, as the number of employers to check decreased, the bot was able to check each remaining employer more often. I didn’t want to spam the website with requests, and the script was naturally limited by the 4 second sleep time I used to wait for the requisite JavaScript to render so the script could search the content on the webpage.
Here’s some of the emails that ‘cambotslambot’ sent:
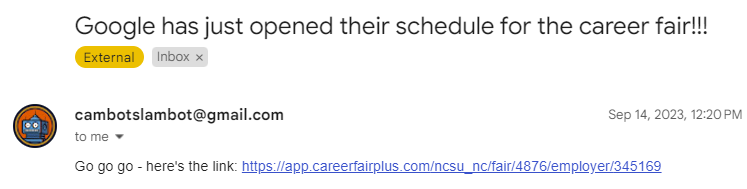
The email I received when Google opened their time slots

The email I received when the bot encountered an error

Over the course of two weeks, the bot checked the career fair website over 70,000 times
What I accomplished:
- 1-on-1 meetings with 7 companies:
- Google (1st slot!)
- Lucid Software
- Cisco
- Fidelity Investments
- Blue Cross & Blue Shield
- Live Oak Bank
- Prometheus Group
- 1 final round interview (and hopefully more soon!)
- Got 2 of my friends 1-on-1 slots with Google
- Had fun!
Problems I overcame and what I learned from them:
-
Problem: The script couldn't find the schedule element on the webpage.
What I learned: Even when the browser.get() function call is done, you can't always grab and parse the page's content immediately. It takes time for the browser to be fully rendered. In this case, I used a static sleep to solve this, but I could've also used Selenium's implicit wait mechanism. This might've even allowed me to circumvent the use of the Beautiful Soup package. -
Problem: The Raspberry Pi stopped running the script when I exited my ssh session.
What I learned: The screen command can be used to launch one or more shell sessions from an ssh session (paraphrased from geeksforgeeks.org). This was handy because I use ssh to connect to my Raspberry Pi from my desktop (that Pi is running Ubuntu Server 23.04, by the way). For this project, I created a shell session using screen, started the script, detached from that session using Ctrl-a + d, then exited the ssh session. This allowed the script to continue running on my Pi in the detached shell session even after the ssh session was terminated.
What I’d like to change if I did it again:
- A better monitoring solution. Getting emails from the bot was fun, but there are better ways to do it. Last summer, I worked for an SRE team at Centene and it would be super cool to have a dashboard like Dynatrace for my raspberry pi to monitor processes and performance metrics like memory and cpu usage. Something like this.
- A smarter way of waiting for the webpage to load than a static 4 second wait. I'm sure there are better ways (something like Selenium's implicit wait, mentioned above), but for a small script like this, I went for the first solution that came to mind. Waiting for only the required amount of time would make the script faster at checking each webpage.
- A faster library. Selenium is super cool, but kind of slow. Something like the Requests-HTML library might be faster, and it has support for JavaScript (then again it uses Chromium under the hood so I doubt it's much faster...).
- Multithreading or multiprocessing - I'd have one thread or process to check the webpage for each employer, and I'd kill off each one when their employer uploads timeslots. Something like this.
All in all, this was a very fun and satisfying little project simply because it worked and it had tangible results. Whether anything will come from these interviews, only time will tell. Thanks for reading!